
Particle Swarm Optimization: a parallelized approach
Informazioni generali
Parallel Particle Swarm Optimization (PSO) è una nota tecnica di ottimizzazione.
In PSO, una particella è un’entità fondamentale caratterizzata da:
- Una componente di posizione, indicata con $x$, che rappresenta una possibile soluzione per il problema di ottimizzazione.
- Una componente di velocità, indicata con $v$, che viene utilizzata per perturbare la posizione della particella.
- Una misura di performance, indicata come $f(x)$ o valore di fitness, che quantifica la qualità della soluzione candidata.
L’intero insieme di particelle forma uno “sciame”.
Ogni particella deve percepire le posizioni e le misure di performance associate delle particelle vicine. Questo permette a ogni particella di conoscere la posizione migliore tra le sue vicine ($z$) e la propria migliore prestazione ($y$) ottenuta.
Questo progetto implementa una versione di PSO che impiega un approccio “basato su distanza”. In particolare, ogni particella mantiene un numero fisso di vicini, che si regola dinamicamente in base alla posizione della particella nella regione di spazio.
Parametrizzazione
PSO prevede diversi parametri:
- Dimensione dello sciame, tipicamente intorno alle 20 particelle per problemi con una dimensionalità che va da 2 a 200.
- Dimensione del vicinato, in genere da 3 a 5 vicini o un vicinato globale.
- Fattori di aggiornamento della velocità.
Ottimizzazione
L’algoritmo di PSO inizia con la preparazione di uno sciame di particelle, a cui vengono assegnate posizioni e velocità casuali.
Durante ogni iterazione, ogni particella aggiorna la propria velocità utilizzando l’equazione:
$$v' = w \cdot v + \phi_1 U_1 \cdot (y - x) + \phi_2 U_2 \cdot (z - x)$$Qui:
- $x$ e $v$ rappresentano la posizione e la velocità corrente della particella.
- $y$ e $z$ indicano rispettivamente la miglior posizione personale e quella sociale/globale.
- $w$ indica il fattore d’inerzia che tiene conto della velocità corrente.
- $\phi_1$ e $\phi_2$ sono coefficienti di accelerazione o tassi di apprendimento, che regolano rispettivamente le influenze cognitive e sociali.
- $U_1$ e $U_2$ sono numeri casuali distribuiti uniformemente tra 0 e 1.
Successivamente, ogni particella aggiorna la propria posizione utilizzando:
$$x' = x + v'$$In caso di miglioramento delle prestazioni, la particella aggiorna il suo miglior punteggio personale ($y$) e potenzialmente il miglior punteggio globale ($z$).
Analisi dello stato dell’arte
Le implementazioni PSO esistenti si possono dividere in tre categorie:
- Algoritmi che modificano il comportamento di PSO introducendo nuove caratteristiche.
- Implementazioni di PSO focalizzate sulla risoluzione di specifici problemi del mondo reale.
- Implementazioni di PSO volti ad ottimizzare la velocità di esecuzione del runtime.
Il progetto esclude dall’analisi la seconda categoria di problemi in quanto queste implementazioni sono fortemente dipendenti dal problema che cercano di svolgere. La prima categoria, invece, è adatta all’analisi di benchmarking, ma spesso richiede modifiche al codice, con potenziali problemi. La terza categoria, volta all’ottimizzazione della velocità di esecuzione, è stata identificata come concorrente principale della nostra implementazione.
| Rif. | Anno | Tipologia | Codice | Note |
|---|---|---|---|---|
| Kennedy, J. and Eberhart, R. | 1995 | Serial | No | - |
| toddguant | 2019 | Seriale | Sì | 1 |
| sousouho | 2019 | Seriale | Si | 1 |
| kkentzo | 2020 | Seriale | Sì | 1 |
| fisherling | 2020 | Seriale | Si | 1 |
| Antonio O.S. Moraes et al. | 2014 | MPI | No | - |
| Nadia Nedjah et al. | 2017 | MPI/MP | No | - |
| abhi4578 | 2019 | MPI/MP,CUDA | Sì | 1 |
| LaSEEB | 2020 | OpenMP | Sì | 2 |
| pg443 | 2021 | Seriale,OpenMP | Sì | 1 |
Gli indici nelle note si riferiscono a:
- l’approccio fornisce solo l’implementazione del vicinato globale. Il confronto con queste metodologie non sarebbe veritiero, poiché queste implementazioni hanno un chiaro vantaggio nel tempo di esecuzione grazie a una topologia favorevole;
- l’approccio fornisce PSO con diverse versioni di neighborhood ma senza un approccio basato sulla distanza. Dunque, le implicazioni sono le stesse del punto 1.
Parallelizzazione
Questo progetto si è concentrato sulla parallelizzazione utilizzando un approccio ibrido OpenMP-MPI. Introduce strategie di multiprocessing e di comunicazione efficiente per migliorare le prestazioni di PSO.
Versione seriale dell’algoritmo
Le fasi principali dell’algoritmo di PSO comprendono l’inizializzazione delle particelle, lo scambio di posizioni tra gli sciami, l’ordinamento delle particelle in base alla distanza e gli aggiornamenti di posizione e velocità. I primi tentativi di parallelizzazione con OpenMP hanno rivelato un overhead significativo per problemi di piccole dimensioni, con conseguenti tempi di esecuzione più lenti rispetto al modello a singolo thread.
Versione parallela dell’algoritmo
Il carico di lavoro è stato distribuito tra più processi utilizzando la libreria MPI e il multiprocessing è stato utilizzato tramite OpenMP per vari jobs a memoria condivisa.
Architettura
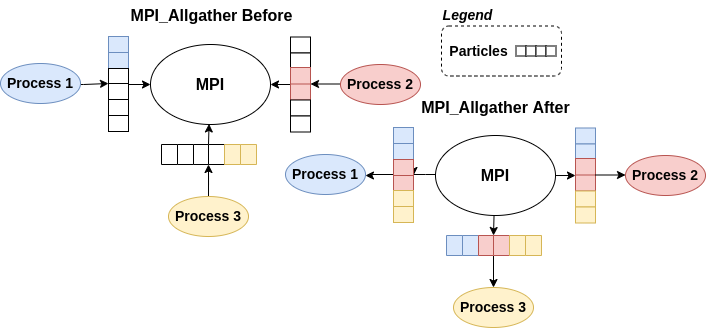
È stato implementato un modello di calcolo parallelo, il modello “all-to-all”, utilizzando MPI_Allgather per scambiare messaggi individuali tra tutti i processi.
Messaggio
Per facilitare la comunicazione tra processi, è stato introdotto un tipo di dati MPI personalizzato denominato “broadcastMessage_t”, che contiene informazioni quali timestamp, numero di iterazione, identificatore di particelle, rank del mittente e dati della soluzione.
Schema di comunicazione
La comunicazione tra i processi è sincrona. Ogni processo gestisce una parte delle particelle e le informazioni sulle particelle vengono scambiate utilizzando MPI_Allgather. L’ordinamento delle particelle permette a ciascun processo di identificare i vicini più prossimi delle singole particelle.
Benchmarking
È stata condotta un’analisi di benchmarking completa variando il numero di thread, processi e modelli di allocazione dei processi PBS. La configurazione primaria comprendeva una dimensione del problema di 50, 5000 particelle, 500 iterazioni e altri parametri rilevanti.
I risultati hanno rivelato che per la parallelizzazione dei thread, l’overhead introdotto da OpenMP spesso supera i vantaggi in termini di prestazioni. La parallelizzazione dei thread è risultata inadeguata per tutti i problemi a causa del comportamento variabile dei diversi sistemi.
I benchmark si sono concentrati principalmente sulla soluzione multiprocesso. I risultati hanno mostrato che con l’aumentare del numero di processi aumenta anche il tempo necessario per la comunicazione. Lo scenario ottimale è stato osservato quando si è utilizzato un numero limitato di processi, poiché l’overhead associato alla comunicazione MPI è diventato significativo con un numero maggiore di processi.
Discussione finale
È stato implementato con successo un algoritmo ibrido OpenMP-MPI per la risoluzione di problemi complessi di ottimizzazione continua, dotato di una robusta pipeline DevOps.
La parallelizzazione dei thread si è rivelata inefficace per PSO, portando spesso a un degrado delle prestazioni a causa dell’eccessivo overhead.
Collaboratori
- Samuele Bortolotti
- Federico Izzo