
Particle Swarm Optimization: a parallelized approach
Allgemeine Informationen
Das Projekt Parallele Partikelschwarmoptimierung (PSO) befasst sich mit dem Bereich der Optimierungstechniken und konzentriert sich in erster Linie auf die Konzepte der “Partikel” und der “Partikelwahrnehmung”.
Im Kontext von PSO ist ein Partikel eine fundamentale Entität, die durch Folgendes gekennzeichnet ist:
- Eine Position, bezeichnet als $x$, die einen Lösungsvorschlag für ein Optimierungsproblem darstellt.
- Eine Geschwindigkeitskomponente, bezeichnet als $v$, die zur Störung der Position des Partikels verwendet wird.
- Ein Leistungsmaß, das als $f(x)$ oder Fitnesswert bezeichnet wird und die Qualität des Lösungskandidaten quantifiziert.
Die gesamte Ansammlung von Partikeln bildet einen “Schwarm”.
Jedes Teilchen muss die Positionen und die zugehörigen Leistungswerte der benachbarten Teilchen kennen. Auf diese Weise kann sich jedes Teilchen die Position der besten Leistung ($z$) seiner Nachbarn und seine eigene beste Leistung ($y$) bis zum aktuellen Punkt merken.
In diesem Projekt wird eine Version von PSO implementiert, die einen “distanzbasierten” Nachbarschaftsansatz in Form der nächsten Nachbarn verwendet. Konkret hat jedes Partikel eine feste Anzahl von Nachbarn, die sich dynamisch an die Position des Partikels in der Landschaft anpasst.
Parametrisierung
Der PSO-Algorithmus umfasst mehrere kritische Parameter:
- Schwarmgröße, typischerweise etwa 20 Partikel für Probleme mit einer Dimensionalität von 2 bis 200.
- Nachbarschaftsgröße, typischerweise zwischen 3 und 5 Nachbarn oder eine globale Nachbarschaft.
- Faktoren für die Geschwindigkeitsaktualisierung.
Kontinuierliche Optimierung
Das PSO beginnt mit der Initialisierung eines Schwarmes von Partikeln, denen jeweils zufällige Positionen und Geschwindigkeiten zugewiesen werden.
Während jeder Iteration aktualisiert jedes Teilchen seine Geschwindigkeit unter Verwendung der Gleichung:
$$v' = w \cdot v + \phi_1 U_1 \cdot (y - x) + \phi_2 U_2 \cdot (z - x)$$Hier:
- $x$ und $v$ stehen für die aktuelle Position und Geschwindigkeit des Teilchens.
- $y$ und $z$ bezeichnen die persönlich beste bzw. die sozial/global beste Position.
- $w$ steht für das Trägheitsgewicht, in das die aktuelle Geschwindigkeit eingeht.
- $\phi_1$ und $\phi_2$ sind Beschleunigungskoeffizienten oder Lernraten, die kognitive bzw. soziale Einflüsse steuern.
- $U_1$ und $U_2$ sind Zufallszahlen, die gleichmäßig zwischen 0 und 1 verteilt sind.
Anschließend aktualisiert jedes Teilchen seine Position mit:
$$x' = x + v'$$Bei einer Leistungsverbesserung aktualisiert das Partikel seine persönliche Bestleistung ($y$) und möglicherweise die globale Bestleistung ($z$).
Analyse des Stands der Technik
Eine Überprüfung der bestehenden PSO-Implementierungen ergab drei Hauptkategorien:
- Algorithmen, die das PSO-Verhalten durch die Einführung neuer Funktionen modifizieren.
- PSO-Implementierungen, die sich auf die Lösung spezifischer Probleme der realen Welt konzentrieren.
- Bemühungen zur Optimierung der Ausführungsgeschwindigkeit zur Laufzeit.
Das Projekt schließt die zweite Kategorie aus, da diese Lösungen stark problemabhängig sind. Die erste Kategorie eignet sich für Benchmarking-Analysen, erfordert jedoch häufig Codeänderungen, was zu potenziellen Inkonsistenzen führt. Die dritte Kategorie, die auf die Optimierung der Laufzeitgeschwindigkeit abzielt, ist der Hauptkonkurrent, und es wurden verschiedene PSO-Versionen implementiert.
| Ref. | Jahr | Typ | Code | Hinweis |
|---|---|---|---|---|
| Kennedy, J. und Eberhart, R. | 1995 | Seriell | Nein | - |
| toddguant | 2019 | Seriell | Ja | 1 |
| sousouho | 2019 | Seriell | Ja | 1 |
| kkentzo | 2020 | Seriell | Ja | 1 |
| fisherling | 2020 | Seriell | Ja | 1 |
| Antonio O.S. Moraes et al. | 2014 | MPI | Nein | - |
| Nadia Nedjah et al. | 2017 | MPI/MP | Nein | - |
| abhi4578 | 2019 | MPI/MP,CUDA | Ja | 1 |
| LaSEEB | 2020 | OpenMP | Ja | 2 |
| pg443 | 2021 | Seriell,OpenMP | Ja | 1 |
Die Indizes in den Anmerkungen beziehen sich auf:
- bietet nur globale Nachbarschaftsimplementierung. Damit wäre der Vergleich nicht wahrheitsgemäß, da diese Implementierungen aufgrund einer günstigen Topologie einen klaren Vorteil in der Ausführungszeit haben;
- bietet PSO mit verschiedenen Nachbarschaftsversionen an, aber ohne einen abstandsbasierten Ansatz. Daher sind die Implikationen dieselben wie bei Punkt 1.
Hauptschritt zur Parallelisierung
Dieses Projekt konzentrierte sich auf die Parallelisierung mittels eines hybriden OpenMP-MPI-Ansatzes. Es führte Multiprocessing und effiziente Kommunikationsstrategien ein, um die PSO-Leistung zu verbessern.
Serielle Version des Algorithmus
Zu den Kernschritten des PSO-Algorithmus gehören die Initialisierung der Partikel, der Positionsaustausch zwischen dem Schwarm, die Sortierung der Partikel auf der Grundlage der Entfernung sowie die Aktualisierung von Position und Geschwindigkeit. Anfängliche Versuche, den Algorithmus mit OpenMP zu parallelisieren, ergaben einen erheblichen Overhead für kleine Probleme, was zu langsameren Ausführungszeiten im Vergleich zum Single-Thread-Modell führte.
Parallele Version des Algorithmus
Die Arbeitslast wurde mit Hilfe der MPI-Bibliothek auf mehrere Prozesse verteilt, und Multiprocessing wurde durch OpenMP für verschiedene Shared-Memory-Aufgaben genutzt.
Architektur
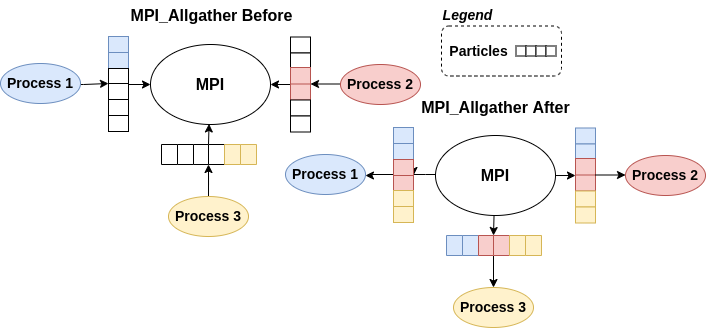
Ein paralleles Berechnungsmuster, das “All-to-All”-Modell, wurde mit MPI_Allgather implementiert, um einzelne Nachrichten zwischen allen Prozessen auszutauschen.
Nachricht
Um die Kommunikation zwischen den Prozessen zu erleichtern, wurde ein eigener MPI-Datentyp namens “broadcastMessage_t” eingeführt, der Informationen wie Zeitstempel, Iterationsnummern, Partikelidentifikatoren, Absenderränge und Lösungsdaten enthält.
Kommunikationsmuster
Die Kommunikation zwischen den Prozessen erfolgte synchron. Jeder Prozess bearbeitete einen Teil der Partikel, und die Partikelinformationen wurden mit MPI_Allgather ausgetauscht. Die sortierten Partikel ermöglichten es jedem Prozess, die nächsten Nachbarn für einzelne Partikel zu identifizieren.
Benchmarking
Es wurde eine umfassende Benchmarking-Analyse durchgeführt, bei der die Anzahl der Threads, Prozesse und PBS-Prozesszuweisungsmuster variiert wurde. Die primäre Konfiguration umfasste eine Problemdimension von 50, 5000 Partikel, 500 Iterationen und andere relevante Parameter.
Die Ergebnisse zeigten, dass bei der Thread-Parallelisierung der durch OpenMP verursachte Overhead die Leistungsvorteile oft übersteigt. Die Thread-Parallelisierung erwies sich aufgrund des unterschiedlichen Verhaltens der verschiedenen Systeme als ungeeignet für alle Probleme.
Das Benchmarking konzentrierte sich hauptsächlich auf die Multiprozesslösung. Die Ergebnisse zeigten, dass mit zunehmender Anzahl der Prozesse auch die für die Kommunikation benötigte Zeit anstieg. Das optimale Szenario wurde bei der Verwendung einer begrenzten Anzahl von Prozessen beobachtet, da der mit der MPI-Kommunikation verbundene Overhead bei einer größeren Anzahl von Prozessen erheblich wurde.
Abschließende Diskussion
Im Rahmen des Projekts wurde erfolgreich ein hybrider OpenMP-MPI-Algorithmus für komplexe kontinuierliche Optimierungsprobleme entwickelt, der mit einer robusten DevOps-Pipeline ausgestattet ist.
Die Thread-Parallelisierung erwies sich für PSO als ineffektiv und führte aufgrund des übermäßigen Overheads häufig zu Leistungseinbußen. Benchmarking
Mitwirkende
- Samuele Bortolotti
- Federico Izzo