
Unsupervised Domain Adaptation
Informazioni generali
Progetto di gruppo per il corso di Deep Learning della Laurea Magistrale in Informatica dell’Università di Trento.
Descrizione e obiettivi
L’obiettivo principale di questo progetto è costruire, addestrare e valutare un framework di deep learning su un setting standard di Unsupervised Domain Adaptation (UDA).
Il dataset su cui vengono testati i metodi proposti è Adaptiope, un dataset UDA diversificato e su larga scala con tre domini: dati sintetici, di prodotto e dal mondo reale.
Le reti implementate sono addestrate:
- in modo supervisionato sul dominio di origine;
- in modo non supervisionato sul dominio target.
Per valutare la qualità della strategia di allineamento dei domini si utilizza il gain, ossia l’entità del miglioramento ottenuto utilizzando il framework di domain adaption rispetto al risultato ottenuto senza alcun approccio di domain adaption. Il guadagno può essere rappresentato matematicamente come:
$$ G = acc_{uda} - acc_{so} $$Questo viene fatto in entrambe le direzioni tra i due domini selezionati, usando come metrica di valutazione la accuratezza di validazione sul dominio di destinazione:
$$ Accuratezza = \frac{T_P + T_N}{T_P + T_N + F_P + F_N} $$Dove:
- $TP$ indica i veri positivi, cioè i casi in cui l’algoritmo ha previsto correttamente la classe positiva.
- $TN$ indica i veri negativi, cioè i casi in cui l’algoritmo ha previsto correttamente la classe negativa.
- $FP$ sta per falsi positivi, ossia i casi in cui gli esempi vengono erroneamente associati alla classe positiva mentre appartengono a quella negativa. (noto anche come “errore di tipo I”).
- $FN$ indica i falsi negativi, ossia i casi in cui gli esempi vengono erroneamente alla classe negativa mentre appartengono a quella positiva. (noto anche come “errore di tipo II”).
Alla fine i limiti inferiori e superiori sono calcolati addestrando le reti solo su un dominio specifico (dominio di origine per un limite inferiore, dominio di destinazione per un limite superiore), consentendoci di fornire alcune considerazioni sui risultati delle nostre architetture.
Domain adaptation
Per fornire un background formale, ci basiamo sulla definizione di Domain Adaptation fornita da Gabriela Csurka et.al, presentata nella sottosezione seguente.
Definiamo un dominio $D$ come uno spazio di feature d-dimensionale $X \ in \mathcal{R}^d$ basato su una distribuzione di probabilità marginale $P(X)$, e un task $T$ è definito come una distribuzione di probabilità condizionale $P(Y|X)$ dove $Y$ è lo spazio delle etichette. Dato un insieme di esempi $X = \{x_1, \cdots x_n\}$ di $X$ e le corrispondenti etichette $Y = \{y_1, \cdots y_n\}$ di $Y$. In generale, questi accoppiamenti feature-etichetta $\{x_i, y_i\}$ possono essere utilizzati per apprendere la distribuzione di probabilità $P(Y|X)$ in modo supervisionato. Supponiamo di avere due domini con i relativi compiti: un dominio sorgente $D_s = {X_s, P(X_s)}$ con $T_s = {Y_s, P(Y_s|X_s)}$ e un dominio target $Dt = {X_t, P(X_t)}$ con $T_t = {Y_t, P(Y_t|X_t)}$. Se i due domini corrispondono, ossia $D_s = D_t$ e $T_s = T_t$, per risolvere il problema si possono utilizzare i metodi tradizionali di machine learning, dove $D_s$ diventa l'insieme di addestramento e $D_t$ l'insieme di test. Tuttavia, se questa ipotesi viene violata, $D_t \neq D_s$ o $T_t \neq T_s$, i modelli addestrati su $D_s$ potrebbero avere scarse prestazioni su $D_t$, oppure non sono direttamente applicabili se $T_t \neq T_s$. Inoltre, quando il dominio di origine è correlato a quello di destinazione, è possibile sfruttare le informazioni correlate di ${D_s, T_s}$ per apprendere $P(Y_t|X_t)$.Questo processo è noto come transfer learning.
Domain adaptation si riferisce in genere a problemi in cui i task rimangono gli stessi ($T_t = T_s$), ma i domini differiscono ($D_s \neq D_t$). Nelle attività di classificazione, si presuppone che sia l'insieme di etichette che le distribuzioni condizionali siano condivise tra i due domini, ovvero $Y_s = Y_t$ e $P(Y|X_t) = P(Y|X_s)$. Tuttavia, la seconda ipotesi, $P(Y|X_t) = P(Y|X_s)$, è piuttosto forte e potrebbe non essere sempre valida negli scenari del mondo reale. Di conseguenza, la definizione di domain adaptation è spesso semplificata per richiedere solo la prima assunzione, vale a dire $Y_s = Y_t = Y$.Inoltre, il campo di domain adaptation distingue due scenari:
- Domain adaptation non supervisionato, dove le etichette sono disponibili solo per il dominio di origine.
- Domain adaptation semi-supervisionato, in cui viene etichettato solo un numero limitato di esempi target.
Soluzioni proposte
Quando si affrontano i problemi di Deep Domain Adaptation, esistono tre approcci principali:
- Metodi basati sulla discrepanza: questi metodi allineano la rappresentazione dei dati del dominio utilizzando misure statistiche.
- Metodi basati su confusione: implicano un discriminatore di dominio per imporre un fattore di confusione nel modello in modo che non risca a riconoscere il dominio di appartenenza dei vari esempi.
- Metodi basati sulla ricostruzione: questi metodi utilizzano un’attività di ricostruzione ausiliaria per garantire una rappresentazione delle caratteristiche invarianti dal dominio.
Questa repository include soluzioni per ciascuno di questi metodi, nonché una soluzione personalizzata che ne combina due: basata sulla discrepanza e basata sulla ricostruzione (“DSN” + “MEDM”).
A causa della disponibilità limitata di esempi, la costruzione di una rete non pre-addestrata non ha prodotto risultati soddisfacenti. Pertanto, iniziamo con una rete pre-addestrata sul set di dati di per il riconoscimento degli oggetti ImageNet.
Inoltre, per esplorare a fondo i metodi proposti, vi è la possibilità di valutare il metodo di domain adaptation utilizzando due diverse reti backbone: AlexNet e ResNet18.
Architetture
Per affrontare in modo efficace il problema di domain adaptation, abbiamo implementato varie architetture di rete adattate paper pertinenti e adattate alle nostre esigenze.
Il nostro obiettivo primario, come affermato nell’introduzione, è valutare le prestazioni (gain) di alcuni degli approcci più significativi nel campo di domain adaptation, integrati con due delle più importanti architetture di reti neurali convoluzionali: AlexNet e ResNet.
In questa repository trattiamo:
- Deep Domain Confusion Networks
- Domain Adversarial Neural Network
- Domain Separation Networks
- Rotation loss Network
- Entropy Minimization vs. Diversity Maximization for Domain Adaptation
- Il nostro tentativo di combinare “MEDM” con “DANN”.
- Un altro approccio per combinare “MEDM” con “DSN”.
Risultati
In questo progetto, abbiamo esplorato varie categorie di architettura per le tecniche di domain adaptation, tra cui “basate sulla discrepanza”, “basate sul confusione” e “basate sulla ricostruzione”. In particolare, gli approcci più efficaci sono stati “DANN” e “MEDM”.
“MEDM” è un approccio versatile che può essere perfettamente integrato in qualsiasi architettura, caratterizzato da due semplici loss basate su entropia che si traducono in un allenamento stabile e ottime prestazioni. Al contrario, “DANN” è più suscettibile alle variazioni degli iperparametri e spesso porta a un addestramento instabile.
Durante i nostri esperimenti, abbiamo scoperto che la combinazione di “DSN” e “MEDM” si è rivelata efficace, mentre la combinazione di “MEDM” e “DANN” non ha prodotto miglioramenti costanti.
Domain adaptation dal dominio dei prodotti al mondo reale è più impegnativo, ma offre un maggiore potenziale di miglioramento poiché c’è più spazio tra il limite inferiore e il limite superiore. Al contrario, la transizione tra le immagini del mondo reale e quelle del prodotto garantisce una maggiore precisione perché le reti sono state pre-addestrate su “ImageNet”. Di conseguenza, il divario tra lo scenario di riferimento e il mondo reale è più ridotto, rendendo più impegnativi progressi significativi.
Dopo aver testato sia “AlexNet” che “ResNet18” come architetture backbone, abbiamo scoperto che non solo “ResNet18” mostrava valori di base e limite superiore più elevati, ma tutte le strategie di domain adaptation hanno anche generato gain sostanzialmente maggiori.
I grafici t-SNE hanno dimostrato chiaramente che la nostra soluzione finale estrae in modo efficace le caratteristiche rilevanti da entrambi i domini mantenendo una classificazione accurata. Le distribuzioni assomigliano molto a quelle ottimali, rappresentate dal modello ResNet18 limite superiore.
Grafici di allineamento della distribuzione
Abbiamo incluso grafici che illustrano come le feature dei domini di destinazione e di origine vengono distribuite utilizzando tecniche di dimensionality reduction.
In questo caso mostriamo il problema di domain adaptation dal dominio dei prodotti al mondo reale, concentrandoci sul modello con le migliori prestazioni, vale a dire “DSN” + “MEDM”. Per fornire una rappresentazione efficace dell’allineamento, presentiamo due grafici:
- La distribuzione delle feature apprese dalla rete neurale backbone (ResNet18 in entrambi i casi), esclusi i layer di classificazione e collo di bottiglia.
- La distribuzione delle classi predette.
Idealmente, vogliamo che il nostro modello di domain adaptation raggiunga prestazioni simili a quelle del modello del limite superiore, che fornisce la migliore generalizzazione sia per i campioni di dominio di origine che di destinazione. Pertanto, la distribuzione delle feature del modello è una metrica preziosa per valutare la qualità della tecnica di domain adaptation.
Distribuzione delle feature del modello del limite superiore sul set di test:
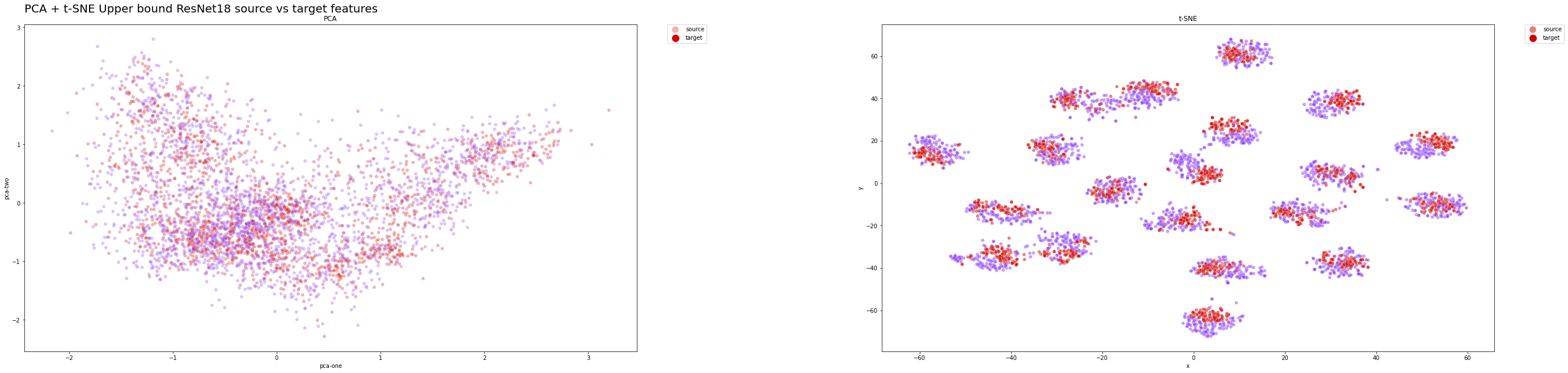
Distribuzione delle classi del modello del del limite superiore sul set di test:

Ci aspettiamo che sia la distribuzione delle classi che quella delle feature si allineino strettamente con le distribuzioni target, poiché il modello ha raggiunto prestazioni notevoli.
Distribuzione delle funzionalità DSN + MEDM sul set di test:
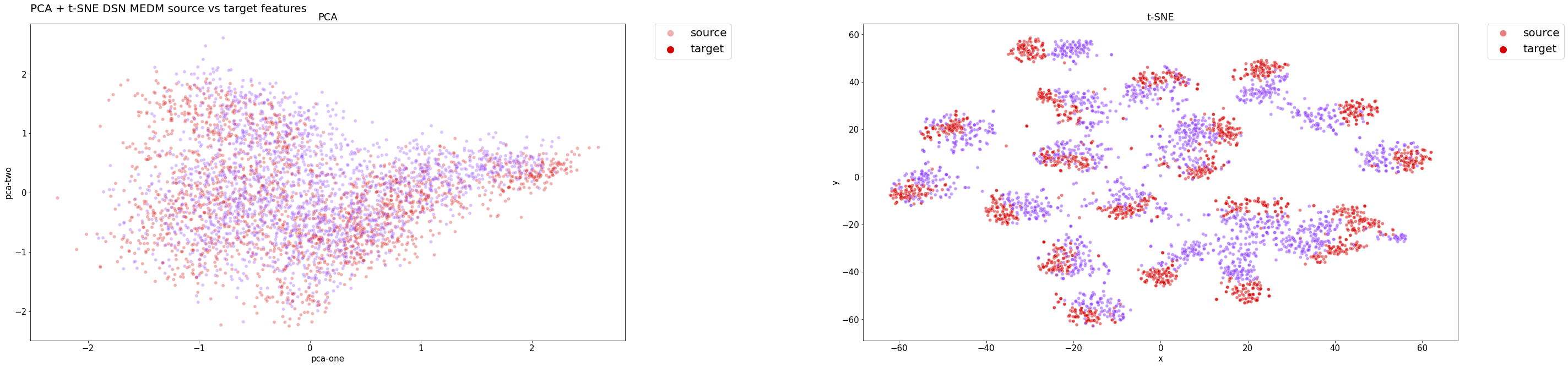
Come evidenziato dalle distribuzioni delle classi riportate di seguito, il classificatore del modello raggruppa efficacemente gli esempi mantenendo un’elevata precisione. I cluster sono ben definiti e separati, anche per gli esempi di domini di destinazione, che sono correttamente classificati.
Distribuzione delle classi DSN + MEDM sul set di test:
In entrambi i casi, la PCA non ha fornito informazioni significative sui risultati, poiché una trasformazione lineare potrebbe essere troppo semplicistica per ridurre i dati ad alta dimensione a un incorporamento di dimensione inferiore.
Prestazione
Ecco i risultati che abbiamo ottenuto sulla versione più piccola di Adaptiope:
| Backbone Network | Metodo | Solo sorgente | Solo target | Accuratezza sul target (\%) | Gain |
|---|---|---|---|---|---|
| AlexNet | Solo sorgente | Immagini di Prodotti | Vita Reale | 64.45 | 0 |
| ResNet18 | Solo sorgente | Immagini di Prodotti | Vita Reale | 75.39 | 0 |
| AlexNet | Limite superiore | Immagini di Prodotti | Vita Reale | 85.94 | 21.485 |
| ResNet18 | Limite superiore | Immagini di Prodotti | Vita Reale | 96.88 | 20.312 |
| AlexNet | DDC | Immagini di Prodotti | Vita Reale | 68.36 | 3.91 |
| ResNet18 | DDC | Immagini di Prodotti | Vita Reale | 83.50 | 8.11 |
| AlexNet | DANN | Immagini di Prodotti | Vita Reale | 65.23 | 0.78 |
| ResNet18 | DANN | Immagini di Prodotti | Vita Reale | 87.11 | 11.72 |
| DSN Originale | Immagini di Prodotti | Vita Reale | 04.17 | ||
| AlexNet | BackboneDSN | Immagini di Prodotti | Vita Reale | 58.85 | -5.60 |
| ResNet18 | BackboneDSN | Immagini di Prodotti | Vita Reale | 78.39 | 3.00 |
| ResNet18 | OptimizedDSN | Immagini di Prodotti | Vita Reale | 81.25 | 5.86 |
| ResNet18 | Rotation Loss | Immagini di Prodotti | Vita Reale | 73.83 | -1.56 |
| ResNet18 | MEDM | Immagini di Prodotti | Vita Reale | 90.36 | 14.97 |
| ResNet18 | MEDM + DANN | Immagini di Prodotti | Vita Reale | 80.21 | 4.82 |
| ResNet18 | MEDM + DSN | Immagini di Prodotti | Vita Reale | 91.15 | 15.76 |
| AlexNet | Solo sorgente | Vita Reale | Immagini di Prodotti | 85.55 | 0 |
| ResNet18 | Solo sorgente | Vita Reale | Immagini di Prodotti | 93.75 | 0 |
| AlexNet | Limite superiore | Vita Reale | Immagini di Prodotti | 95.70 | 10.15 |
| ResNet18 | Limite superiore | Vita Reale | Immagini di Prodotti | 98.05 | 4.3 |
| AlexNet | DDC | Vita Reale | Immagini di Prodotti | 82.03 | -3.52 |
| ResNet18 | DDC | Vita Reale | Immagini di Prodotti | 94.53 | 0.78 |
| AlexNet | DANN | Vita Reale | Immagini di Prodotti | 83.98 | -1.57 |
| ResNet18 | DANN | Vita Reale | Immagini di Prodotti | 96.09 | 2.34 |
| OriginalDSN | Vita Reale | Immagini di Prodotti | 04.17 | ||
| AlexNet | BackboneDSN | Vita Reale | Immagini di Prodotti | 84.11 | -1.44 |
| ResNet18 | BackboneDSN | Vita Reale | Immagini di Prodotti | 91.41 | -2.34 |
| ResNet18 | DSN Ottimizzata | Vita Reale | Immagini di Prodotti | 93.49 | -0.26 |
| ResNet18 | Rotation Loss | Vita Reale | Immagini di Prodotti | 91.80 | -1.95 |
| ResNet18 | MEDM | Vita Reale | Immagini di Prodotti | 97.14 | 3.39 |
| ResNet18 | MEDM + DANN | Vita Reale | Immagini di Prodotti | 94.00 | 0.25 |
| ResNet18 | MEDM + DSN | Vita Reale | Immagini di Prodotti | 96.61 | 2.86 |
Contributori
- Samuele Bortolotti
- Luca De Menego